Recent advancements in 3D foundation models have enabled the generation of high-fidelity assets,
yet precise 3D manipulation remains a significant challenge. Existing 3D editing frameworks often face a
difficult trade-off between visual controllability, geometric consistency, and scalability.
Specifically, optimization-based methods are prohibitively slow, multi-view 2D propagation techniques
suffer from visual drift, and training-free latent manipulation methods are inherently bound by frozen
priors and cannot directly benefit from scaling.
In this work, we present ShapeUP, a scalable, image-conditioned 3D editing framework
that formulates editing as a supervised latent-to-latent translation within a native 3D representation.
This formulation allows ShapeUP to build on a pretrained 3D foundation model, leveraging its strong
generative prior while adapting it to editing through supervised training.
In practice, ShapeUP is trained on triplets consisting of a source 3D shape, an edited 2D image, and
the corresponding edited 3D shape, and learns a direct mapping using a 3D Diffusion
Transformer (DiT). This image-as-prompt approach enables fine-grained visual control over both
local and global edits and achieves implicit, mask-free localization, while maintaining strict structural
consistency with the original asset.
ShapeUP results across a range of geometry and texture edits. Click any example to expand.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
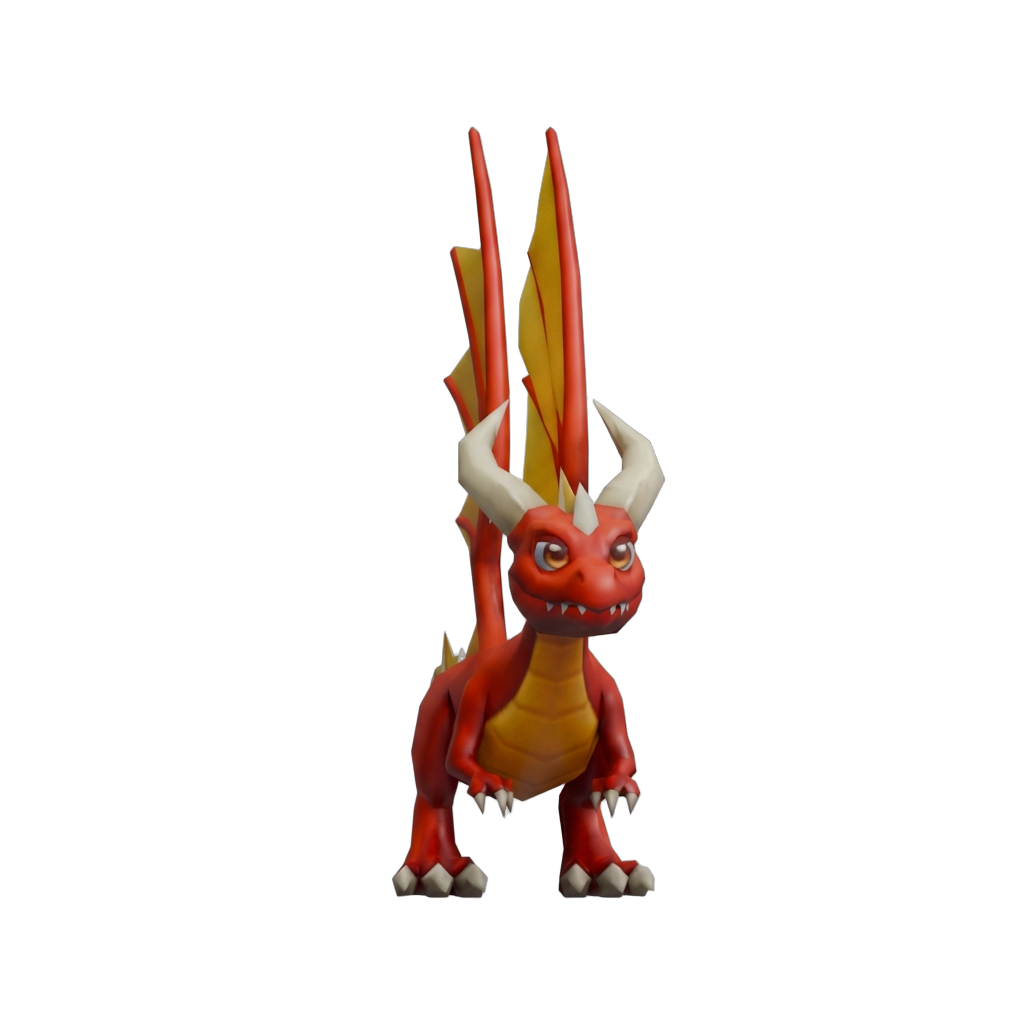 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
 Edit Cond.
Edit Cond.
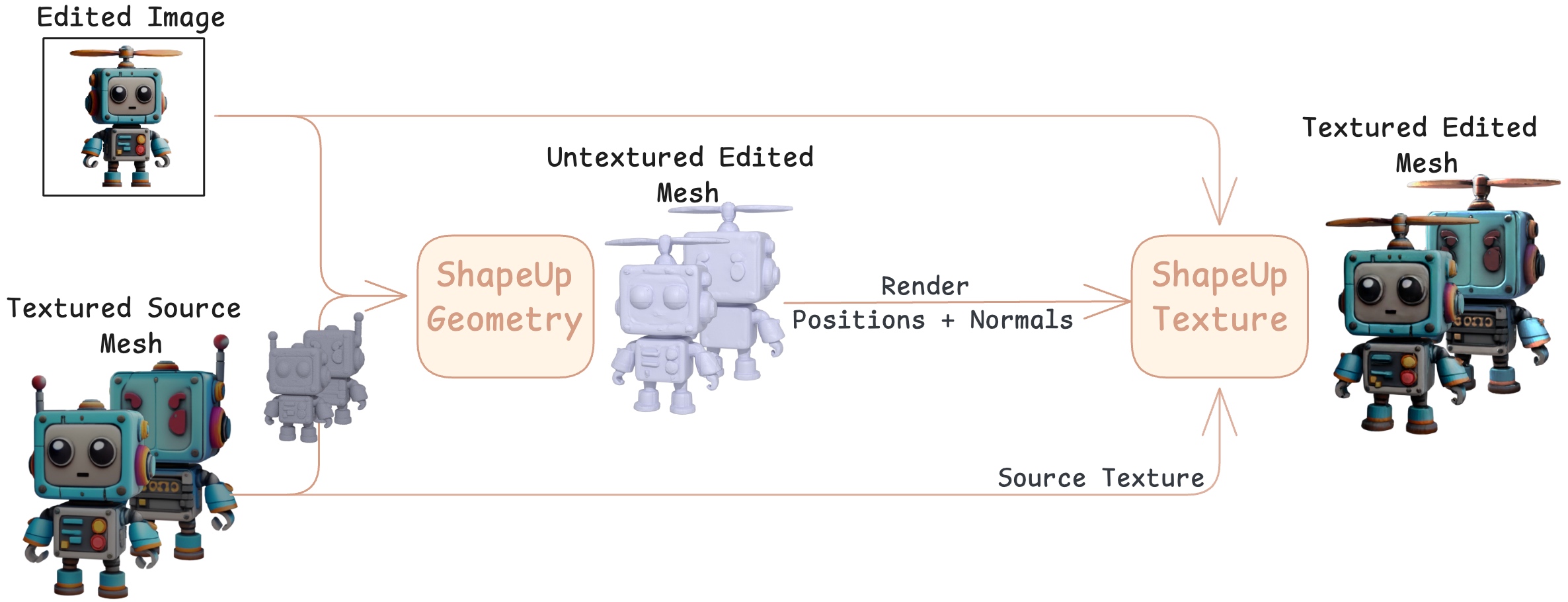
Method Overview. ShapeUP formulates image-guided 3D editing as a supervised latent-to-latent translation within a pretrained 3D Diffusion Transformer. Given a source shape and an edit-conditioning image, ShapeUP produces an edited 3D asset with faithful geometry and appearance while preserving unedited regions.
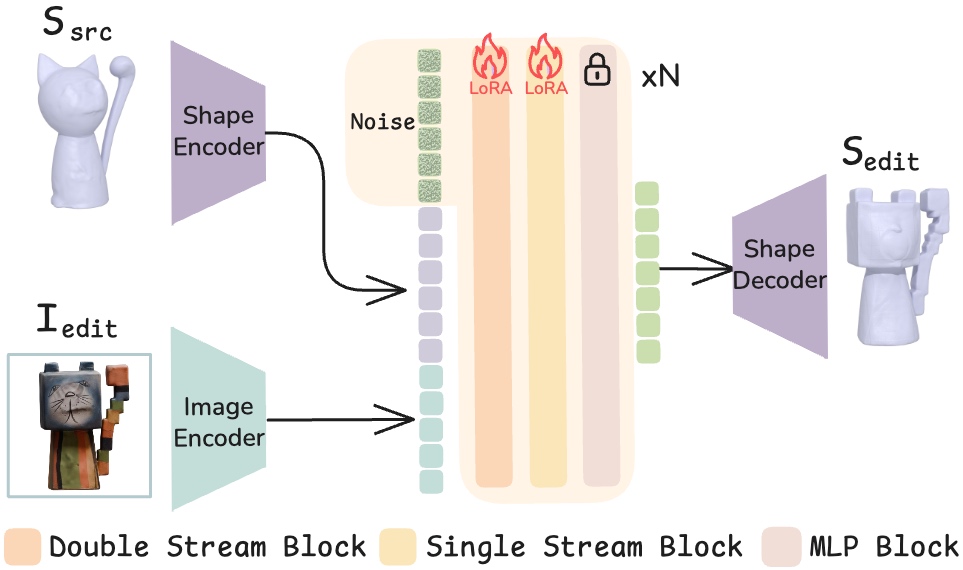
Geometry Editing Pipeline. ShapeUP encodes the source 3D shape into the latent space of a pretrained Step1X-3D DiT, then conditions diffusion on both the subsampled shape latents and the image prompt via LoRA adapters trained on the MMDiT backbone. The model learns to translate the source shape into the edited target geometry while preserving structural identity.
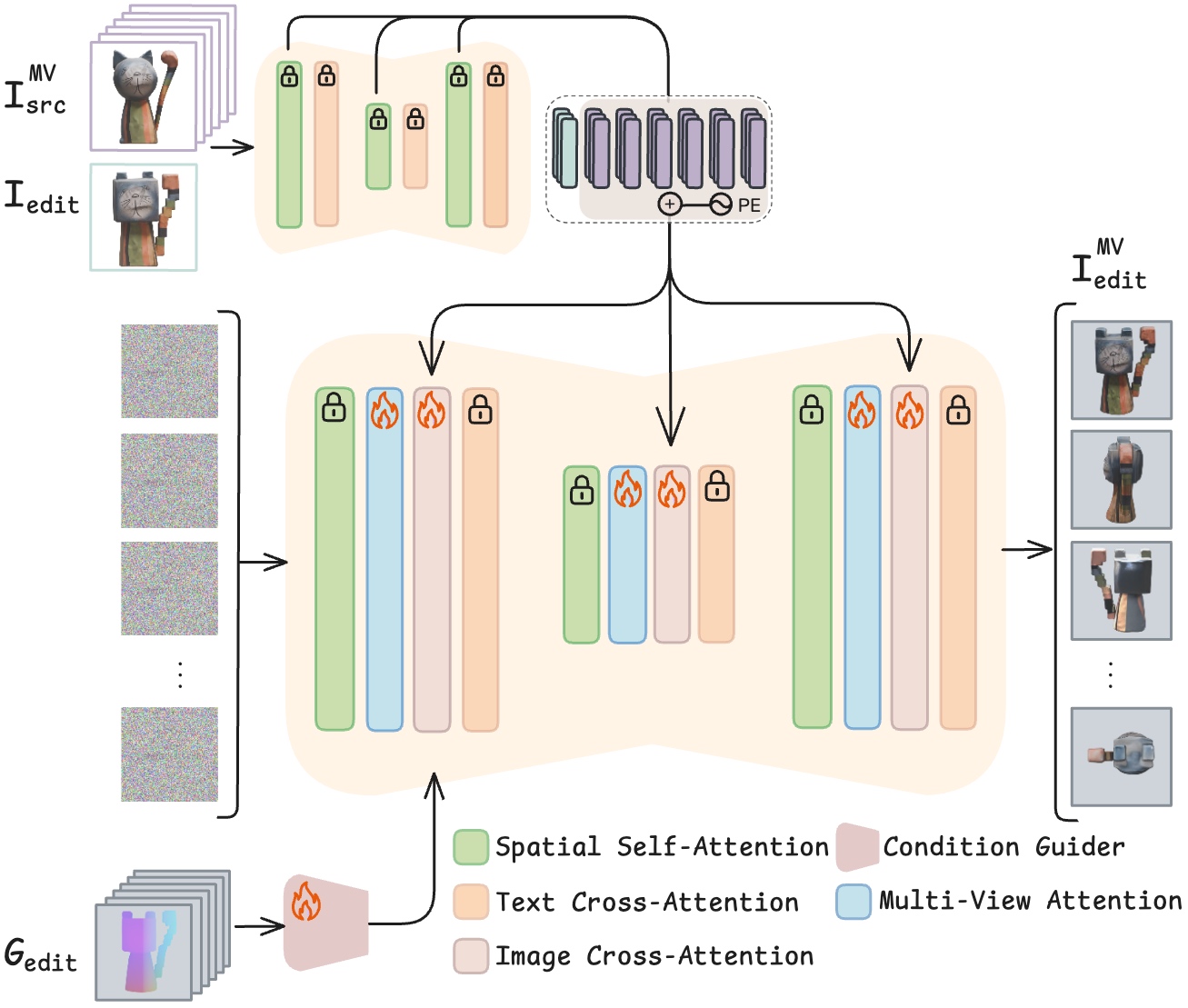
Texture Editing Pipeline. Multi-view renders of the source shape are injected through the model's cross-attention layers alongside the edit conditioning image. View-axis positional encodings distinguish source-texture tokens from edit tokens, enabling the model to synthesize consistent appearance that respects both the edit and the original fine-grained texture details.
Quantitative comparison on BenchUp. We evaluate image-guided 3D shape editing by measuring Condition Alignment and Occluded Region Fidelity. ShapeUP outperforms all baselines across every metric, demonstrating superior edit fidelity without sacrificing preservation of unedited regions.
| Method | Condition Alignment | Occluded Region Fidelity | |||||
|---|---|---|---|---|---|---|---|
| SSIM ↑ | LPIPS ↓ | CLIP-I ↑ | DINO-I ↑ | C-Dir ↑ | CLIP-I ↑ | DINO-I ↑ | |
| 3DEditFormer | 0.733 | 0.270 | 0.908 | 0.849 | 0.441 | 0.877 | 0.736 |
| EditP23 | 0.759 | 0.254 | 0.917 | 0.851 | 0.455 | 0.880 | 0.748 |
| ShapeUP (Ours) | 0.763 | 0.198 | 0.943 | 0.915 | 0.520 | 0.928 | 0.878 |
Ablation study. We evaluate the impact of the number of latent vectors and DFM training data on geometry editing, and compare texture conditioning strategies. Using 1024 latents with DFM data achieves the best overall balance of condition alignment and occluded region preservation.
| Variant | Condition Alignment | Occluded Region Fidelity | |||||
|---|---|---|---|---|---|---|---|
| SSIM ↑ | LPIPS ↓ | CLIP-I ↑ | DINO-I ↑ | C-Dir ↑ | CLIP-I ↑ | DINO-I ↑ | |
| w/o DFM data | 0.769 | 0.196 | 0.943 | 0.909 | 0.505 | 0.932 | 0.884 |
| 256 latents | 0.766 | 0.206 | 0.941 | 0.909 | 0.525 | 0.917 | 0.869 |
| 512 latents | 0.768 | 0.220 | 0.918 | 0.868 | 0.506 | 0.905 | 0.837 |
| Concat MV (texture) | 0.779 | 0.187 | 0.943 | 0.912 | 0.555 | 0.897 | 0.832 |
| ShapeUP (Ours) | 0.763 | 0.198 | 0.943 | 0.915 | 0.520 | 0.928 | 0.878 |
Human preference study. Participants viewed the source object, target edit, and two results (ours vs. one baseline) in a two-alternative forced-choice setup, selecting the result that better achieves the edit while preserving the original. ShapeUP was strongly preferred across all criteria. Results from 664 comparisons by 34 participants.
Each row shows the rotating source mesh, edit condition image, and results from all three methods. Videos play automatically as you scroll.
@article{gat2026shapeup,
title={ShapeUP: Scalable Image-Conditioned 3D Editing},
author={Gat, Inbar and Cohen Bar, Dana and Levy, Guy and Richardson, Elad and Cohen-Or, Daniel},
journal={Preprint},
year={2026}
}
